

文/浪潮人工智能研究院
“源 1.0”自 2021 年 9 月底发布以来收获了广泛的关注。其参数量达 2457 亿,超越美国 OpenAI 组织研发的 GPT-3。“源 1.0”在语言智能方面表现优异,获得中文语言理解评测基准 CLUE 榜单的零样本学习(zero-shot)和小样本学习(few-shot)两类总榜冠军。测试结果显示,人群能够准确分辨人与“源 1.0”作品差别的成功率低于 50%。
在之前的博客中,我们详细论述了如何准备预训练数据、模型本身如何训练,以及在下游任务如何提升精度。在本篇中,我们将着重讨论模型的结构问题,以及由模型结构带来的效果。会回答以下三个问题:(1)“源 1.0”基础模型结构是怎样的?(2)为什么要选择这样的结构?(3)和模型结构相关的下游任务效果。
1. “源1. 0”基础模型结构的选择
在介绍基础模型结构之前,显然要明确一件事情:我们想让模型完成什么呢?在自然语言处理(NLP)领域,所有的任务大体可以被分为两类:自然语言理解(NLU)任务和自然语言生成(NLG)任务,前者偏重于对语义的理解,而后者偏重于文本的创作。如果可能的话,开发者当然期望这个模型在两类任务上同样出色,但事实上,不同类型的 NLP 模型结构对两类任务总是有所偏重的。如果只考虑在榜单上的表现,偏重于 NLU 任务可能会比较合适,因为包括“源 1.0”冲击的 CLUE 榜单在内,几乎所有相似的榜单都偏重于自然语言理解任务,在 《中文巨量模型浪潮“源 1.0”的小样本学习优化方法》(http://blog.itpub.net/31545803/viewspace-2847859/)这篇博文上也可以看到相关任务的介绍。为了在榜单上取得更好的成绩,自然应该选择一个偏重于 NLU 的模型结构。然而,当我们考虑到模型实际应用的时候,就会发现 NLG 的应用场景更广泛,没有 NLG,也很难体先出 NLU 的价值。所以,在这个问题上,我们的认识是要优先保证模型具有出色的创作能力(NLG),而在 NLU 任务上也务必尽可能地提升效果。
带着这样的初衷,“源 1.0”的基础结构为一个单向的语言模型,即根据上文预测下文的概率。其中的 Transformer 解码器(Decoder)采用自回归的方式输出序列。当处理不同的下游任务时,则会根据任务类型使用一个从文本到文本的框架,将所有任务处理成相似的格式,以便直接将预训练的语言模型应用于不同的下游任务上。过去的研究已经证实,经典的单向语言模型结构是擅长 NLG 任务的,而在 NLU 任务上则相对薄弱一些。为了进一步探索模型在 NLU 任务上的可能,在“源 1.0”的开发过程中,我们考虑了语言模型(Language Model,LM),和前缀语言模型(Prefix Language Model,PLM)两种结构。两种结构的主要区别在于掩码的方式,如图 1 所示。
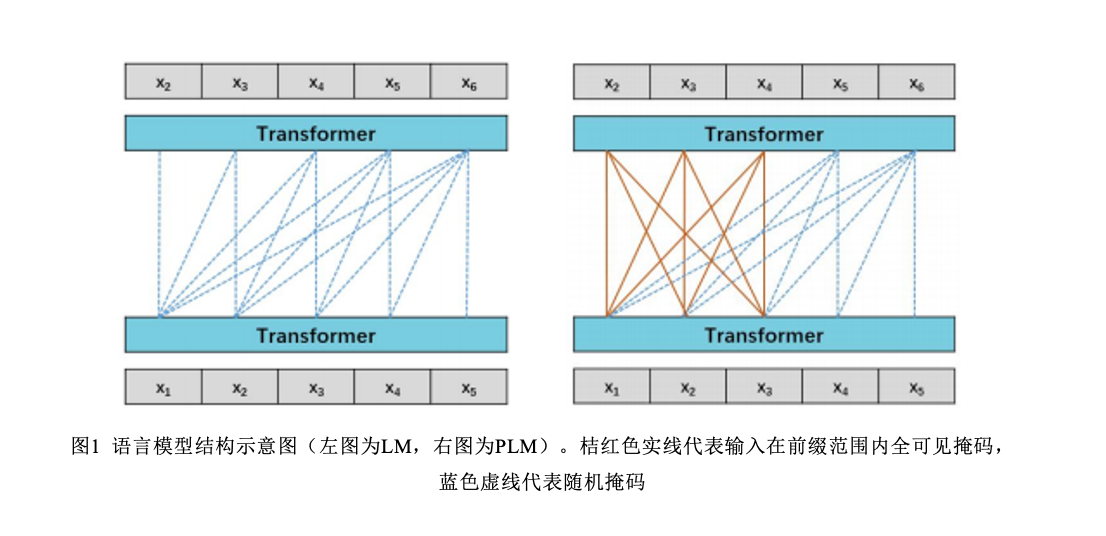
在t时刻,解码器根据模型对输出序列的预测概率,生成输出序列中最右侧的一位 (x5)的标记(token)。之后这个标记与输入序列相连接,一起被送入模型以预测 t+1 时刻的输出(x6)的标记。我们用这两种模型结构分别训练了 130 亿参数量的两个模型,Yuan LM-13B 和 Yuan PLM-13B,并把这两个模型放在小样本学习(FewCLUE)和零样本学习(ZeroCLUE)场景下做了评估(表1)。关于表格中任务的详细介绍,请参考博文《中文巨量模型浪潮“源 1.0”的小样本学习优化方法》。
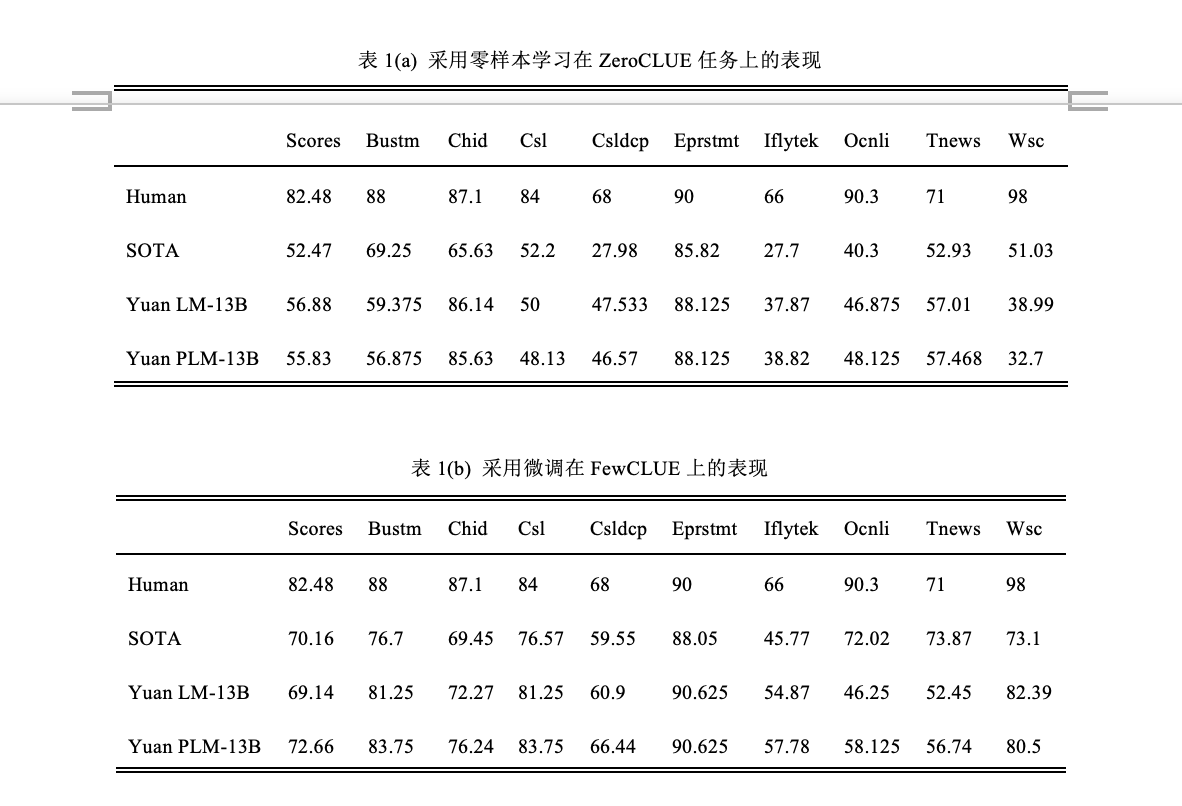
表1(a)和(b)表明 LM 和 PLM 在 Zero-Shot 和 Few-Shot 上都具有优异的表现能力。LM 和 PLM 的零样本平均得分都优于已往的最优结果。在 Csldcp、Tnews 和 Iflytek 任务上,模型的得分大大超过了以往零样本学习的最优结果。模型在 Ocnli 上也取得了不错的成绩,比以往零样本学习的最优结果高出6-8 个点。我们的监督微调方法与 GPT 的设计一致。 LM 和 PLM 的平均分数与以往最优分数相当,如表1(b)所示。与小样本学习结果相比,微调对 Bustm、Csl 和 Wsc 有很大的改进。但是,对于在零样本学习上表现出色的 Chid、Eprsmt、Tnews 和 Ocnli,微调贡献很小甚至会有负面影响。
比较 LM 和 PLM 的结果,我们注意到 LM 在 Zero-Shot 和 Few-Shot 上表现更好,而 PLM 在微调方面表现出色。微调通常会在大多数 NLU 的任务中带来更好的准确性,这与我们一开始选择模型结构的初衷相合。然而,当模型参数量从百亿扩大到千亿规模,比如对于我们的 “源 1.0”模型,微调会消耗大量的计算资源,这是不经济的。所以最终,我们选择 LM 作为“源 1.0”的基础架构。
2. “源 1. 0”的文本生成效果
“源 1.0”更加出色的能力是体现在创作上(NLG)。为了评价模型生成文本的效果,我们任意选择了“源 1.0”生成的 24 个文本,包括 4 副对联、5 首中文传统和现代诗歌、5 篇新闻文章、5 个故事和 5 段对话。对联、诗歌和对话的创作可以看作是短文本任务(~10-20 个标记),而新闻和故事生成可以看作是长文本任务(~300 个标记)。与之对比的人工写的文章来自名家所作的诗歌、经典小说、搜狐新闻的新闻文章和 LCCC-large 数据集中的对话。参与者被要求选择文章是“由人类撰写”还是“由模型撰写”,我们收集了 83 份有效问卷。根据我们的采访,大多数受访者会倾向于选择 “更好的”那一篇是由人类创作的,而“稍差”的那一篇是模型生成的。
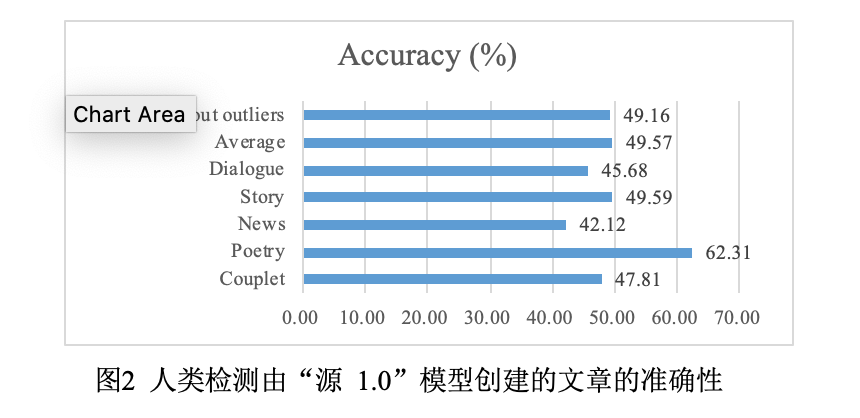
图 2 展示了这次实验的结果。“源 1.0”创作的文章有 49.16% 的概率可以被正确识别为“由模型撰写”,这意味着参与者难以区分人工撰写和模型生成的文章,尤其是现代诗和文章。新闻(42.12%)和故事(49.15%)的生成结果让我们可以相信模型出色的长文本生成能力。在我们的参与者看来,一些模型撰写的文章甚至比部分出自大师之手的文章还要好。对联和诗歌的生成表明,尽管我们的预训练语料中没有加强古汉语,“源 1.0”也能够创建具有一定形式的古汉语文本,如图 2 所示。“源 1.0”也可以进行符合人类期望的对话(45.68%)。“源 1.0”目前能够生成多种高质量的文本,如新闻稿件、故事续写等。对于这些类别的任务,所产出的文章与人类创作的内容相差无,甚至达到了以假乱真的程度。
在表 2 中展示了一些“源 1.0”对不同文体的驾驭能力,读者可以稍加体会。

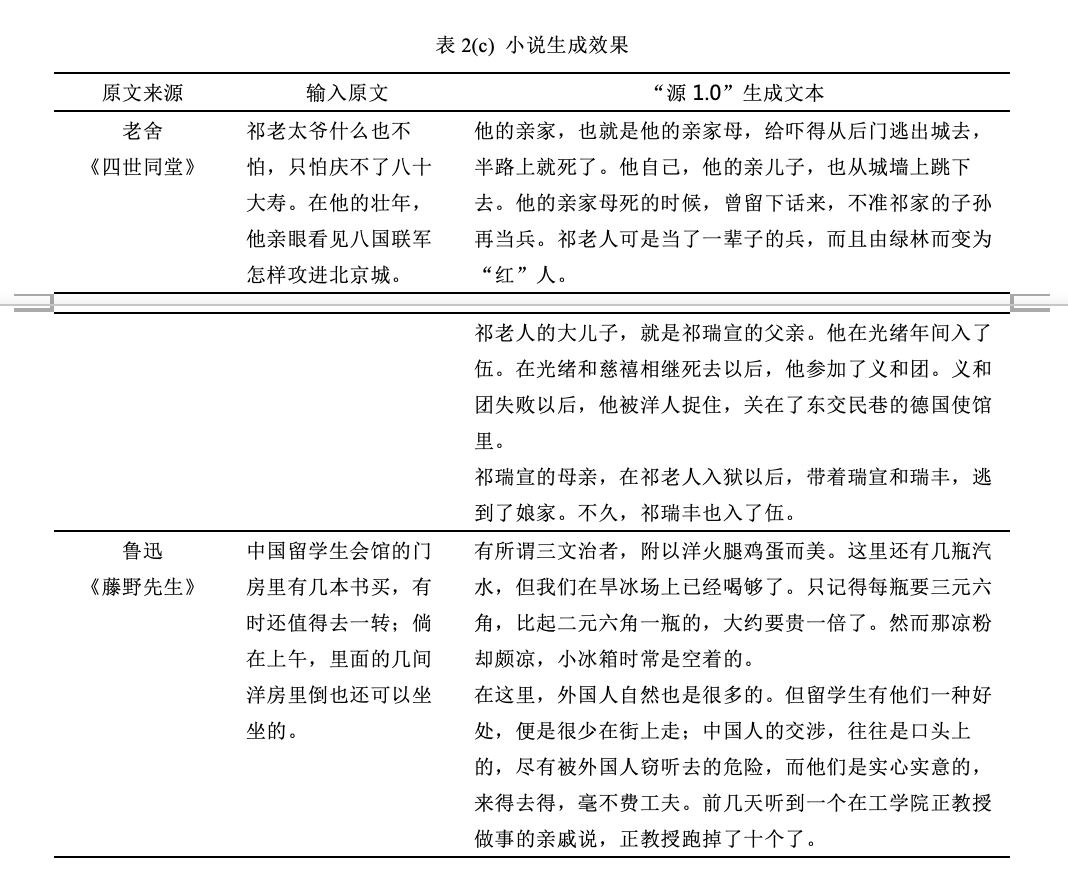

从表2(b)(c)中,我们可以看到“源 1.0”的学习和模仿能力。在生成诗歌时,如果我们在输入中给出某种风格的例子,模型就会倾向于生成相似风格的诗歌。在小说续写中,模型也会依据输入文本的风格,继续文章的写作。
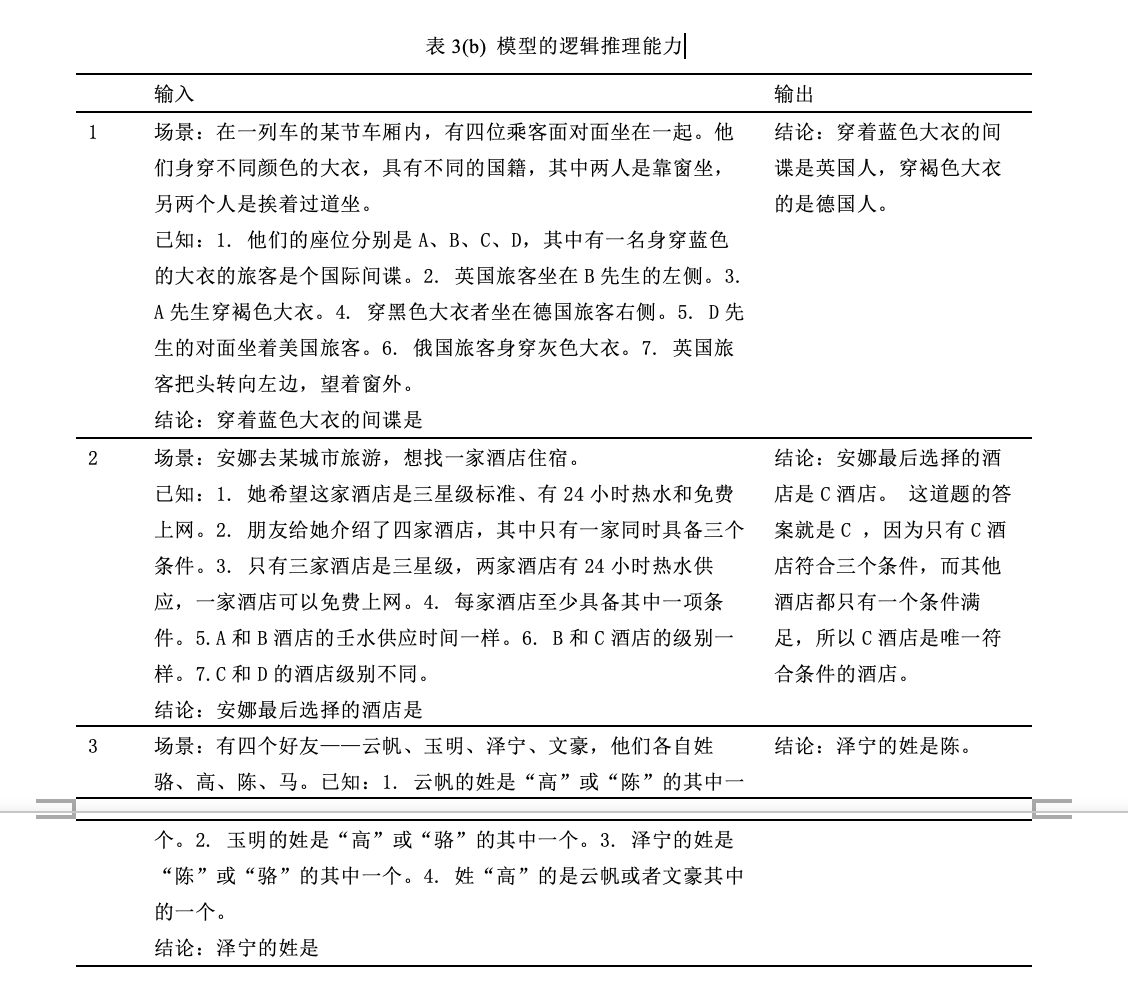
除了基本的创作能力以外,“源 1.0”其实还有一些有趣的能力,比如,模型可以学习一些原本不存在的词的用法,也能够具备一定的推理能力。比如我们在输入中给出了这个词的定义和例句,模型将用给定的信息编写一个新句子。这个不存在词包括名词和形容词。表3(a)显示了模型在 One-shot 条件下的生成结果。在所有情况下,模型都对我们给出的新词作出了近似正确的应用,这意味着我们的模型具有学习和模仿能力。这种能力在模型辅助科学文章写作时特别有效,因为对“源 1.0”来说学术文章中的大量定义可能是陌生的。表3(b)则展示了模型的逻辑推理能力,这些推理题对于人类来说尚有一定的挑战、需要相当程度的推理和计算,但是模型却可以快速给出答案,且正确率远高于随机。

关于“源 1.0”的更多信息,大家可以参照浪潮人工智能研究院发布在 arxiv 上的论文:https://arxiv.org/abs/2110.04725。

24小时阅读排行
最新新闻
